

As we announced today – I’ve joined the board of the non-profit group Investorside. This is a trade association with a mission to “increase investor and pensioner trust in the U.S. capital markets system through the promotion and use of investment research that is financially aligned with investor interests”.
The need for a group like Investorside grew out of the mistrust investors felt for research after the research/banking conflicts became visible in 2001. Sellside researchers were promoting stocks long after they knew they were a bad investment, in order to keep the investment banking fees, and so their own fees going.
Today the group’s members are investment research firms “providing research that works purely for investors”.
FirstRain is used by investors and by corporations today – both when the goal is to do institutional grade research from the web. When I was approached to get involved in Investorside, and to serve on the board, I thought it was a very good fit. It’s an opportunity for me to help the research community using my experience in web 2.0 and growing markets, and it’s an opportunity for me (and FirstRain) to continue to grow in our understanding of the research needs of the investment community.
Here’s the expanded mission:
The Investorside Research Association serves its members through three primary functions:
Certifying Research Providers — Investorside certifies that its members are free of investment banking, consulting, and research-for-hire conflicts and provides certified member firms with the trademarked Investorside Seal.
Promoting the Growth of Independent Research — Through Investorside.org, annual conferences and regular media communication, Investorside markets its member firms to individual and institutional investors.
Promoting Government Policy that Encourages the Use of Independent Research — Investorside represents its members’ interests before regulators, law-makers and members-of-industry, promoting the use of investment research that is aligned with investor interests.

I was struck by the juxtaposition of two articles in the last 24 hours
- Thomson Reuters plan to take share from Bloomberg and
- NYSE releasing real time quotes to the public.
Seemingly unrelated right?
Underlying both is a theme of how the ongoing trend to free content is shaping their competitive strategies and responses.
Thomson Reuters believes it can use price to take Bloomberg market share – Bloomberg being notorious for having fixed pricing and not discounting – and being expensive as a result. And the impact of free web content impacts how users view the terminals:
Neither company has sorted out a strategy for competing with online services. Michael F. Holland, the chairman of Holland & Company and the former chief executive of First Boston’s asset management division, said he can no longer justify a Bloomberg terminal for his current role and often turns to the Web for data. He first used a terminal in the 1980s and remains a fan: “There really is nothing else that’s quite like the Bloomberg,” he said. “From the beginning, it has provided incredible information. But at a very high price.”
And when asked what Google Finance and Yahoo Finance might mean for Bloomberg’s future over time, Mr. Grauer paused. “I don’t know how to answer that,” he said. “I really don’t know how to answer that.”
And John Blossom’s comment in his summary of NYSE’s move is right on:
It is, unfortunately, a familiar refrain in the content industry: major institution covets proprietary content revenues, squeezes them out for as long as possible while the markets move to find both acceptable substitutes and better ways of doing business. Publishing is in essence a very conservative business, so it’s not surprising that NYSE would try to keep this formula going for so long. But in an era when the buyers of securities have and demand information at least as good as most selling institutions failing to serve the buy side in financial markets effectively is to ignore the fundamental shift in the content industry that empowers people with independent access to content from around the world. Your content may seem safe as a proprietary asset, but if it’s not driving your clients’ profits in its most valuable user-defined contexts it is far from a safe bet in today’s content markets.

One of the technology capabilities we have in our system is looking for patterns in streams of data coming from the web. We use it to tag events, detect events and as a result pull interesting documents out of the web for our clients.
But we’re not alone in this kind of work, obviously. Wired has an article this week about how the EUs joint research team has developed the EMM: European Media Monitor which is designed to detect patterns in the stream of data.
So what patterns does EMM find? Besides sending SMS and email news alerts to eurocrats and regular people alike, EMM counts the number of stories on a given topic and looks for the names of people and places to create geotagged “clusters” for given events, like food riots in Haiti or political unrest in Zimbabwe. Burgeoning clusters and increasing numbers of stories indicate a topic of growing importance or severity. Right now EMM looks for plain old violence; project manager Erik van der Goot is tweaking the software to pick up natural and humanitarian disasters, too. “That has crisis-room applications, where you have a bunch of people trying to monitor a situation,” Van der Goot says. “We map a cluster of news reports on a screen in the front of the room — they love that.”
Clustering technology is being used in ever wider applications to find what’s interesting from the petabytes of data we now see on the web. We’re just one cool application of it, but the technology space itself is fascinating and fast paced.

When we announced our Blog Impact reports earlier this week – where we report on blog traffic and spikes for our users – I talked about how we use a set of algorithms we call FirstRain MarketScore to sort out which ones to include in the statistics at any point in time. This is important to continuously present only only the statistics that matter to the market – to sort the wheat from the chaff.
A cynic might say – how do you do that with any credibility? There are so many and growing all the time? So I thought I’d share some insight on how we do it.
Our goal is to identify the most influential blogs within a specific domain of interest to the user so we can spot emerging trends and anomalies – and we do this by comparing blogs based on three characteristics prominence, reach and authority.
- Prominence is the reputation of a given blog within the target domain, along with assessment of its reputation beyond that domain.
- Reach is assessed based on indicators of viewership within the target domain along with some weight for readership beyond the target domain.
- Authority is assessed based on factors that measure trust for the blog’s judgment on question of judgment and projection.
It’s complex to measure these factors but we can do it because we can run measurements on the content of the blog over time -and it would be impossible to do if we weren’t processing and analyzing the content. By running algorithms on the content we can see factors like:
- domain relevance / focus
- consistency
- originality (not copied from other places)
- syndication (not copied to other blogs)
- productivity (how often is the content relevant to an investment topic – of which we have many thousands)
Of course we also look at the traditional market factors like traffic, backlinks and 3rd party ranking to sanity check our results. And importantly, the model is constructed to yield a highly stratified set with a ‘high bar.’ So a blog which is widely read within the domain, which gets cited by other (especially high authority) blogs on questions of interpretation, and is even occasionally read/cited/quoted beyond the domain would score high.
For example, the Gartner analyst blog which covers the software space might be scored fairly well on prominence and reach, and highly rated on authority within the technology blog domain, but would pale in comparison to an IDC analyst blog which covers the worldwide PC market, which scores more highly on prominence and reach because it gets consistently quoted on global PC shipments in financial industry blogs and the Wall Street Journal.
Combine this scoring approach with our ability to normalize results by domain and by company and you get the ability to pull out interesting changes in volume and subject matter – which fill in the research mosaic and can, sometimes, move the market.
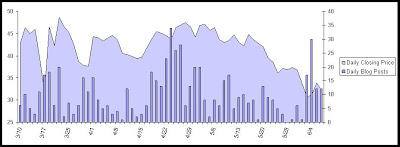
As you can see from our Blog Impact report announcement earlier this week, we’ve been watching blog frequency trends for our clients. I asked my team to do a review of Lehman’s blog stats vs. price and this is what we found. I’m no analyst so I won’t draw a direct correlation – but it is interesting to see the increase in volume of chatter before the price starts to decline and the commonality in the shape of the curves.


I was delighted to check my blackberry at 4:30am this morning on my way to the airport and see a positive reference on FirstRain on Infectious Greed. Paul Kedrosky has been evaluating the system and he posted to his blog:
“I’m trying out the FirstRain markets monitoring service, courtesy of the fine folks there, and so far I highly recommend it”
Alongside of the terrific coverage in Wall Street and Technology today – these made my day.

We announced some important new capabilities to our service today: FirstRain Blog Impact Reports and Capital Market Reports. The key breakthrough is that we can now detect spikes in blogs – which are based on normalized trends over time so you can see when there is truly a change in posting volume – and so quickly see what the blog chatter is that may be impacting the market.
This is an enormous time savings for our users. No more need to set up thousands of RSS readers and troll through them. No more wondering if you are missing rare posts on quiet companies. We’ve determined the most influential blogs at the time, based on our MarketScore algorithms which consider prominence, authority and reach to figure out which blogs to include in your report – and then they are tightly presented as lists linked to the original posts and the FirstRain system.
It’s the first time there is an automated way to systematically include blogs into the investment research process!
The second set of reports are about the capital markets themselves and their interaction with the web. We correlate web results with hedge fund trends, market movers and the short interest – presenting web results directly tied to one of these effects – and in an automated, thorough but prioritized way so our users don’t have to look anywhere else and can quickly see what’s being reported on the web related to the trend.
From our press release:
“… today announced the release of two new qualitative analytics packages-FirstRain Blog Monitor and FirstRain Capital Markets Monitor-that report on the interaction between web results and the market to enable better decisions. These products build on FirstRain’s cutting-edge qualitative analytics technology which distills unstructured data from across the vast web into concise data points and trends that matter to professionals.
“The investing and management communities have largely been without a comprehensive strategy when it comes to understanding and exploiting rich information from the web, particularly the impact that blogs have on the markets,” said Sean O’Dowd, capital markets senior analyst at IDC Financial Insights. “FirstRain’s reports are an important step to bridging this gap in the research process, allowing the analysis of qualitative data on the web beyond just tactical means of tracking names at the peak of market focus.”"
We’re headed to SIFMA in New York this week and very excited to show this new way of using the web as a research database to our users and prospects.

We’ve been doing studies of the volume of unique information on blogs and some interesting facts are coming out. With the exception of prominant tech blogs like TechCrunch, there’s a general lack of understanding/belief in the investment community about whether blogs matter or not so we’ve set out to quantify how often original and meaningful information is published on a blog first.
The challenge with blogs is that while they are exploding in volume, they are often junky and duplicative. And sometimes they are outright copies, called Splogs, designed solely to generate advertising revenue.
It takes technology, like ours, to make sense of the blog world and to identify both the quality of the source and the frequency of original posts so we can quickly identify when a unique (original) piece of information appears on a blog first (and earliest). We not only identify uniqueness, we normalize it to typical volumes by company so we can identify when a change in volume is occurring and so alert our user that there is a change in blog volume, from quality blogs, about his/her company.
When we do exhaustive analysis of blog content vs. news content, across all news sources we process (many, many thousands and far broader than retail aggregators like Google News), we see typically one new, material post per month for 80% of the large cap companies. So, if you are managing a portfolio of 100 equities, we are talking about 80 unique, meaningful pieces of information per month that you will miss – completely unacceptable for the institutional investor. And using RSS readers won’t cut it because of the level of junk and duplication – you’ll miss the one in a thousand that was different and original.